
Retrieval-Augmented Generation (RAG) or fine tuning?
Which of these should you use to tailor your AI to actually deliver value?
Both of these frameworks are shaping the way organizations build smarter, faster, and more relevant AI systems.
But in the growing debate of RAG vs fine tuning LLMs, we understand it’s easy to get lost in technical details. Knowing the difference between retrieval augmented generation vs fine tuning is key to choosing the right method or deciding when to use both.
In this blog, we’ll cover:
If you’ve been comparing fine tuning vs RAG, this guide will make things clear—and help your team build AI that actually works for your goals.
Read Also: Top AI Frameworks In 2025
What Is Retrieval-Augmented Generation (RAG) in AI?
RAG in AI is a method that makes large language models (LLMs) smarter and more accurate by letting them search outside sources—like documents or databases—for information before answering a question. RAG LLMs use a two-step process: a retriever searches for relevant information, and a generator (the LLM) uses it to craft accurate, up-to-date responses.
This makes RAG implementation ideal for fast-changing industries like finance, healthcare, and enterprise tools, where timely information is key. Unlike Fine Tuning LLMs, RAG doesn’t require retraining when data updates, making it faster, cheaper, and highly scalable.
How Does a RAG Workflow Actually Work?
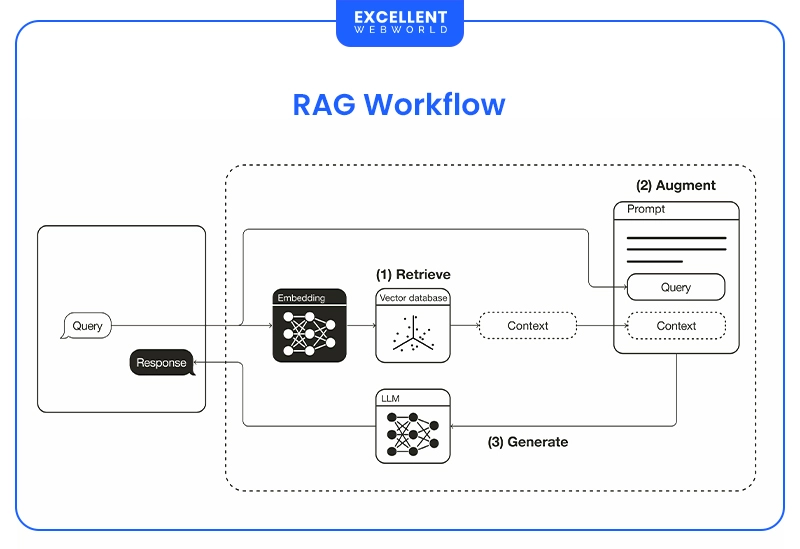
Retrieval-Augmented Generation (RAG) helps LLMs deliver real-time, accurate responses by combining search with generation. Here’s how RAG implementation works in five simple steps:
Compared to fine tuning LLMs, RAG scalability is faster, cheaper, and more flexible. In the RAG vs Fine Tuning LLMs debate, your choice depends on the use case, or use both for the best of both worlds.
What Are the Key Benefits of Using RAG?
When flexibility, speed, and factual accuracy are top priorities, RAG LLMs offer a powerful solution without the overhead of constant model retraining.
| Benefit | Details |
|---|---|
| Reduces Hallucinations | RAG LLMs fetch real facts from trusted sources, so the answers are more accurate and less made-up. |
| Scales to Massive Knowledge Bases | With strong RAG scalability, it can handle millions of documents without slowing down. |
| Cost-Effective AI Model Adaptation | No need to retrain the model every time data changes; RAG implementation updates instantly through your database. |
| Flexible for Real-Time Use | Great for dynamic industries where information keeps evolving, RAG responds with fresh, context-aware outputs. |
| Easy to Customize Without Fine-Tuning | You can plug in different data sources without changing the core model, perfect for agile teams needing fast iterations. |
What Are the Limitations or Challenges of RAG?
While powerful for real-time and dynamic responses, RAG implementation introduces infrastructure and control trade-offs that teams must manage carefully.
| Challenge | Details |
|---|---|
| Relies Heavily on Retrieval Quality | If the retriever fetches the wrong info, even the best RAG LLMs can generate poor answers. |
| More Complex Infrastructure | RAG implementation requires extra tools, like vector databases and embedding models, which means more setup and ongoing maintenance. |
| Latency Can Be an Issue | Since RAG fetches data in real time, it may respond slower than traditional models, something to watch in high-speed applications. |
| Scalability Needs Smart Planning | As data grows, ensuring smooth RAG scalability can become a challenge without the right indexing and system design. |
| Harder to Control Responses | Dynamic input means responses can vary, making AI model adaptation slightly unpredictable at times. |
Where Is RAG Used in Real-World Applications?
What Is Fine-Tuning a Language Model?
Fine-tuning a language model means taking a model that’s already trained and giving it extra training on a specific set of data or task. It’s like teaching a general AI to become really good at one job.
It plays a critical role in the AI development process when businesses need domain-specific performance, consistent tone, or precise behavior. You’ll also need the right LLM deployment services to put the model into production and possibly an LLM integration partner to connect it with your existing systems.
How Does a Fine-Tuning Workflow Actually Work?
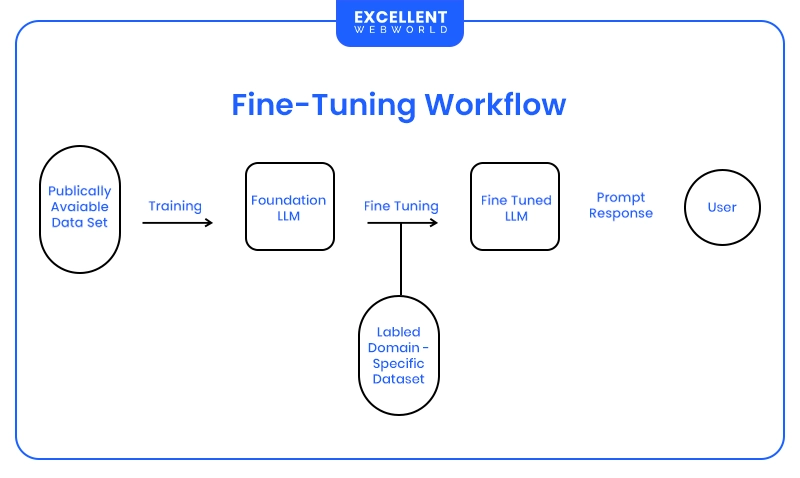
Fine Tuning LLMs involves adapting a general pre-trained model—like GPT or LLaMA—for a specific task or domain. Here’s how fine-tuning implementation works:
It’s ideal when precision and control matter most.
What Are the Advantages of Fine-Tuning a Model?
When precision, control, and brand alignment matter most, fine-tuning LLMs for business use cases delivers unmatched performance and reliability.
| Advantage | Details |
|---|---|
| High Accuracy for Specific Tasks | You can fine-tune LLMs for business tasks like legal writing, support chat, or internal tools, making the model highly precise |
| Faster Inference, No Internet Needed | Fine-tuned models run offline with fast response times, ideal for edge devices or secure environments. |
| Performs Better in Niche Domains | Ideal when your industry language or workflows are too specific for general AI (Think healthcare, law, or finance). |
| Custom Behavior and Brand Voice | You get a model that talks like your brand. Many teams use LLM consulting services or hire LLM developers for this customization. |
| Tight System Integration | Fine-tuned models are easier to embed directly with help from an LLM integration partner or LLM deployment services. |
| Long-Term Consistency | Once trained, a fine-tuned model doesn’t need to search external sources, it “remembers” what matters for your workflows. |
| Efficiency at Scale | Despite the fine-tuning cost and complexity, it pays off for high-volume, repetitive tasks with strict quality standards. |
What Are the Challenges of Fine-Tuning?
Fine tuning LLMs offer deep customization, but come with technical and strategic hurdles that teams must plan for.
| Challenge | Details |
|---|---|
| High Compute Costs | Expensive GPUs and long training times increase the AI development cost. |
| Risk of Overfitting | If the model is trained too narrowly, it might not generalize well, especially in dynamic business environments. |
| Needs Clean, Labeled Data | You’ll need a lot of high-quality examples. Many teams hire LLM developers or rely on LLM consulting services for data prep. |
| Ongoing Maintenance | Any change in data or strategy may require re-tuning. You’ll need a reliable LLM integration partner for long-term updates. |
| Complex Deployment | Getting your fine-tuned model into production isn’t plug-and-play, LLM deployment services help bridge that technical gap. |
| Longer Time to Market | Compared to RAG, fine-tuning can take weeks to build and validate, slowing down fast-moving projects. |
What Is a Common Example Use Case for Fine-Tuning?
What’s the Difference Between RAG and Fine-Tuning?
Choosing between RAG vs fine-tuning for LLMs comes down to your business goals, tech resources, and how often your data changes. Here’s a deeper comparison to help you decide the right LLM customization method for your use case:
| Factor | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
|---|---|---|
| Data Usage | Accesses external knowledge at runtime | Learns from internal training data only |
| Cost | Lower – no need to retrain the model | Higher – includes training, compute, and engineering setup (Fine-tuning cost and complexity) |
| Flexibility | Highly flexible – update documents anytime (RAG scalability) | Less flexible – updates need full retraining |
| Accuracy | High, but depends on retrieval quality (RAG vs model fine-tuning) | High for focused, repetitive tasks (Fine Tuning LLMs) |
| Maintenance | Simple – update knowledge base, not the model | Complex – requires regular retraining |
| Latency | Slightly higher – fetches data during inference | Lower – responses generated instantly |
| Security | Data can remain in external/private databases, good for enterprise control | Data must be fed into the model – requires stricter governance (LLM deployment services) |
| Performance | Variable – depends on retriever speed and search relevance | Consistent and fast if well-trained |
| Complexity | Moderate – requires RAG implementation (retrievers, vector DBs, etc.) | High – needs training pipelines and deployment expertise (LLM consulting services) |
| Data Freshness | Real-time – always uses up-to-date documents | Static – can’t access new data unless re-trained |
| Use Case Fit | Best for fast-changing knowledge or large corpora | Best for stable, domain-specific tasks |
| Deployment | Can run alongside existing systems via APIs | Requires deeper integration – work with an LLM integration partner |
Need help choosing between fine-tuning vs RAG? Keep reading for when to use each or both together.
When Should You Use Retrieval-Augmented Generation (RAG)?
If your business deals with constantly changing information, RAG LLMs are often the smarter choice. In the ongoing debate of RAG vs Fine Tuning LLMs, RAG shines when speed, flexibility, and cost-efficiency matter. Unlike Fine Tuning LLMs, RAG lets you update knowledge instantly, without retraining the model.
Here’s a more detailed breakdown:
Use RAG when:
In the battle of RAG vs model fine-tuning, RAG wins on agility. But if you need consistency and domain memory, fine-tuning vs RAG becomes a deeper conversation.
When Is Fine-Tuning the Better Option?
While RAG LLMs are great for flexibility, there are times when Fine Tuning LLMs is the stronger choice. In the RAG vs Fine Tuning LLMs debate, fine-tuning wins when control, speed, and domain depth really matter. This approach is perfect when the model needs to “remember” how to act without relying on external data.
Here’s when fine-tuning makes sense:
So in RAG vs model fine-tuning, go with fine-tuning when performance and consistency matter more than real-time data. The fine-tuning vs RAG choice isn’t always either/or—but knowing when to use each is key.
Can You Combine RAG and Fine-Tuning? (The Hybrid Approach)
Yes, you can absolutely combine both! In fact, a hybrid approach that blends RAG LLMs with Fine Tuning LLMs is becoming more common, especially in enterprise use cases. When it comes to RAG vs Fine Tuning LLMs, it doesn’t always have to be one or the other. Sometimes, the best solution is to use both together.
How does a hybrid setup work?
You can fine-tune the retriever to better understand your domain or tone, while still using a general-purpose LLM to generate responses. Or, you can fine-tune the generator slightly—just enough to reflect your brand voice—while relying on RAG to provide the latest data.
Example Use Case:
An internal HR chatbot trained to reflect company tone (via fine tuning) while also pulling real-time updates from internal policies, holiday calendars, or new benefits (via RAG implementation) is an example of AI Chatbot Development Services. It feels personalized but stays fresh and accurate.
This hybrid setup gives you the best of both worlds—fast updates from RAG, plus the consistency and context of model fine-tuning. It’s one of the most powerful LLM customization methods available today, especially when balancing flexibility with control.
In the evolving landscape of fine-tuning vs RAG, this hybrid approach is where many forward-thinking teams are headed.
RAG vs Fine-Tuning vs Hybrid: How to Decide?
Choosing between RAG, Fine-Tuning, or a Hybrid Approach depends on your business priorities. Here’s a breakdown to help you choose the right path for your LLM customization methods:
1. Choose RAG when:
2. Choose Fine-Tuning when:
3. Choose Hybrid when:
Still unsure? Hybrid setups often provide the best balance for AI-powered business automation and custom AI model development.
Partner with Excellent Webworld for RAG & Fine-Tuning Solutions
The choice between RAG vs Fine Tuning LLMs depends on your goals. Go for Retrieval Augmented Generation when you need real-time data and quick updates. Choose Fine Tuning LLMs for high accuracy and domain-specific control. Or combine both for flexibility and precision.
Startups can begin with lightweight PoCs to test value fast. Enterprises may benefit from custom solutions that scale with confidence.
That’s where Excellent Webworld comes in. As a top AI development company with 13+ years of software development service expertise, we help you turn AI ideas into real-world apps—fast, scalable, and smart.
Let’s turn your idea into a real-world experience. Book your free consultation today!
Frequently Asked Questions About RAG vs Fine-Tuning
Yes, RAG is ideal when you’re working with a large or constantly changing knowledge base. It retrieves relevant info at runtime, so there’s no need to embed everything into the model like fine-tuning requires.
Absolutely! Both RAG and fine-tuning work with open-source models like LLaMA, Mistral, or Falcon. You just need the right setup—like vector databases for RAG, or training infrastructure for fine-tuning.
Not always. For general tasks, yes—but for narrow domains, even a few thousand well-labeled examples can go a long way. Quality matters more than quantity here.
Yes, but with a trade-off. RAG provides up-to-date answers, but document retrieval can introduce a bit of latency. If speed is critical, you’ll need to optimize your retriever setup.
RAG is usually the more budget-friendly option. You don’t need massive datasets or expensive training runs—just a good document base and smart retrieval logic. It’s an excellent fit for rapid PoCs.

Article By
Mayur Panchal is the CTO of Excellent Webworld. With his skills and expertise, He stays updated with industry trends and utilizes his technical expertise to address problems faced by entrepreneurs and startup owners.


